A Light-Weight Latent Composer
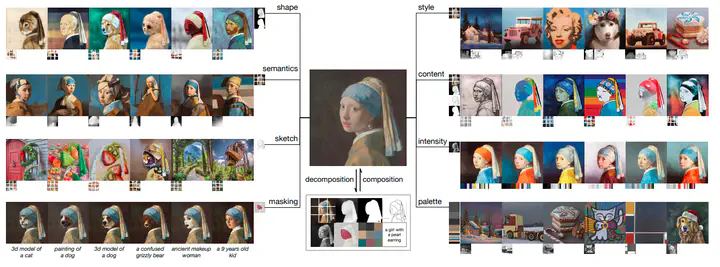 Photo from the paper
Photo from the paperFor this project, I developed a lightweight version of the Composer: Creative and Controllable Image Synthesis with Composable Conditions based on the Latent Diffusion Model. The model provides users with a high degree of control over the image generation process. To achieve this, the input image is decomposed into its representative factors, and a diffusion model is trained on these factors to enable recomposition of the image. During inference, the generation process can be easily controlled by conditioning on different intermediate representations. The decomposed factors represent an enormous design space, which results in highly diverse and rich image content.
To make the proposed architecture lighter, I opted to work directly in the latent space rather than the pixel space, and drew on the general concept of the Latent Diffusion Model to do so. During training, input images undergo a process in the pixel space where they are decomposed into their representative factors, such as color histogram, depth map, and canny edge map. The input images are then encoded into the latent space using a fixed encoder network. The input latent vectors then undergo a forward diffusion process where small amounts of noise are incrementally added until pure Gaussian noise is obtained. At the same time, the intermediate representations are passed through a spatial resizing block to bring them to the same spatial size as the latent vectors. Additionally, text prompts are utilized as an additional conditioning factor. I followed the same conditioning strategy proposed in the original paper by summing the intermediate factors and concatenating the resultant vector with the noise vector. The CLIP image embeddings and text embeddings are projected, concatenated, and sent to the cross-attention layers of the U-Net transformer. For more details, please refer to the paper. During the inference stage, one has the ability to exercise complete control over the generation process by manipulating the representation factors.
Arslan Artykov
PhD student
My research interests include diffusion models, 3D reconstruction, and visual/inertial localization.